The popularity of large language models (LLMs) such as ChatGPT and GPT-4 has taken the world by storm, with enterprises integrating generative AI models into business workflows and governments already taking steps to regulate the technology.
But how can LLMs so quickly provide rich and comprehensive answers to various prompts? Part of the answer lies in the existence of vector databases, which hold several performance advantages over traditional relational database management systems (RDBMS).
What are Vector Databases?
RDBMSs are excellent for storing and retrieving structured data but have well-known limitations when it comes to unstructured data such as free text, video, and images – data types that are extremely common today.
Vector databases are NoSQL databases with advanced search algorithms and indexing able to handle large amounts of complex unstructured data. They do this by storing information as vectors, which are arrays of numbers capable of representing an image, video, or text.
“For instance, the word ‘bank’ might be represented as a 300-dimensional vector in a word embedding model,” writes The New Stack, “with each dimension capturing some aspect of the meaning or usage of ‘bank.’ The vector’s dimensions help us perform a quick semantic search that can easily differentiate between the phrases ‘river bank’ and ‘cash in the bank.’”
How do Vector Databases Work With LLMs?
LLMs also use vectors by transforming text into vector embeddings. These embeddings within language encode the semantic meaning and context of text, allowing LLMs to understand context and judge similarity when returning answers to prompts. Vector embeddings allow LLMs to determine context when looking at a particular word.
“The resulting embeddings encode various aspects of the data, allowing AI models to grasp intricate relationships, detect patterns, and uncover concealed structures,” explains Youssef Hosni of Level Up Coding. “In essence, embeddings serve as a bridge between raw data and the AI system’s ability to make sense of it all.”
Data scientist Simon Thompson describes a vector embedding as a “concept space” with several dimensions that provide context and measure similarity. Thanks to these dimensions, vector databases can define the relationship between multiple vectors by measuring the relative distance between them, with closer numbers indicating similarity and big differences indicating the opposite.
The below image, for example, shows a vector embedding describing cartoon animals using just two dimensions: Color and size. Low numbers represent small, dull animals, and higher numbers represent larger, more colorful animals.
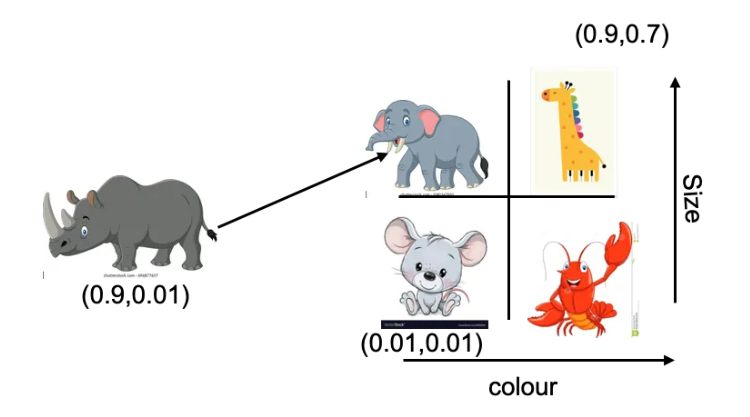
The mouse (bottom left) is small and not very colorful, giving it very low size and color numbers, while the very colorful and large giraffe gets much higher numbers.
While the above is a straightforward representation of a vector embedding, others can get quite complicated: For most BERT models, embeddings can run as high as 768 different dimensions. Thompson illustrates it this way: A model with 1M vectors using a traditional database could take several years to index.
In a general sense, how vector databases work with LLMs is like this:
- Text is converted into vectors and stored in a vector database
- Text being searched due to a prompt is converted into vectors and compared for similarity
- The vectors with the closest matches are selected
- The vectors are converted back into natural language and returned to the user
When models or prompts have thousands of vectors with hundreds of dimensions, vector databases become necessary. The database connected to a LLM must be able to handle the heavy lifting of indexing and querying all those potential data combinations – and as it turns out, vector databases store data as high-dimensional vectors that allow for fast and efficient similarity searches.
Along with the indexing and search of vectors quickly and efficiently, vector databases also enhance the memory of LLMs, which often hallucinate when they don’t have enough information or context. By encoding and storing unstructured data as vectors, these databases allow for semantic/vector search – searching data based on meaning instead of just literally – dramatically improving performance.
Are There Different Kinds of Vector Databases?
The indexing and search system, Facebook AI Similarity Search (Faiss), unveiled by Facebook (now Meta) in 2017, was one of the first-ever vector databases. It’s still renowned for its suitability for high-speed natural language processing (NLP) tasks involving massive data volumes.
But there are other vector databases out there, including:
- Chroma: Open-source vector database able to handle multiple data types and formats, and can be deployed in the cloud or on-premises.
- Pinecone: Cloud-based vector database ideal for real-time applications and large-scale machine learning (ML).
- Weaviate: Open-source vector database that stores vectors and objects, making it ideal for combining vector- and keyword-based searches.
- Milvus: Compatible with ML frameworks such as PyTorch and TensorFlow, making it a popular choice among data scientists and ML engineers.
- DataStax: Its AstraDB vector database can integrate with the Apache Cassandra distributed database.
- MongoDB: A data platform aimed at developers that offers vector search as a feature.
- Vespa: Offers real-time analytics capabilities, along with high data availability and fault tolerance.
Power Up Your AI Innovation With CapeStart
Organizations of all kinds have discovered they can help scale their operations – and employee effectiveness – using LLMs such as ChatGPT and GPT 4, along with customized AI and ML technology and workflows. But not every company has AI expertise on hand, and integrating such advanced technology can often be a big challenge.
Contact us today to learn more about how CapeStart’s data scientists and ML experts can help put your organization on the road to greater efficiency with AI.