How Active Learning, a Form of Machine Learning, Helps Dramatically Reduce Systematic Review Workloads.
The creation and timely dissemination of accurate and exhaustively researched systematic literature reviews (SLRs) is a cornerstone of evidence-based medicine (EBM). But as we’ve discussed in previous blog posts, SLRs take an outsized amount of time to produce – and the most time-consuming part of all usually involves searching for and identifying relevant studies for inclusion.
How long, exactly, do SLRs take? This report indicates around 67 weeks per review. This estimate says between six and 18 months, whereas this one says a minimum of nine to 12 months. Part of that is due to the exponential growth of randomized controlled trial (RCT) literature (there was a nearly 3,000 percent increase in annual RCT output between 1970 and 2000, according to Catalá-López et al).
Bottom line: SLRs take a long time. Because they typically require a team of subject matter experts, independent reviewers, information specialists, and statisticians – among others – they can also be quite expensive (up to US$250,000 per review, according to this estimate).
Any way of lowering time spent on SLRs can save research organizations tens of thousands of dollars per project. And that’s exactly what active learning can achieve when deployed during the article screening phase.
Active learning for systematic literature reviews
Machine learning (ML) and natural language processing (NLP) can, in general, provide a huge productivity boost during SLR creation by automating or semi-automating several manual (and, until now, glacial) processes. These processes include data extraction (which can be improved using named entity recognition techniques), or article screening and selection through active learning.
As noted above, not all ML techniques are suitable for every specific SLR task. When it comes to article screening, El-Gayar et al. say supervised learning techniques “hold very little promise” due partly to a dearth of initial training data (the researchers do say, however, that this type of machine learning works well during the updating of existing SLRs).
The same researchers say active learning can “significantly reduce” time spent on article screening for new systematic literature reviews – even with small initial training datasets.
That’s because active learning algorithms are especially good at choosing the best unlabeled data from which to learn. Active learning systems work by selecting their own training articles to present to a human annotator, who then confirms the relevance of those records.
Thanks to this unique workflow, active learning systems can be especially adept at identifying relevant text in titles and abstracts at recall rates of 95 percent or above (a measurement also known as WSS@95. Ninety-five percent recall rates are a realistic goal of most machine learning projects since rates of 100 percent are next to impossible, even for human reviewers).
The active learning cycle
Active learning isn’t a product that works at that efficiency level out of the box, however. While every classification algorithm differs at least slightly, there’s also a typical set of steps researchers should follow for an active learning system to achieve its task:
- Perform a keyword search and assemble a set of unlabeled data (abstracts and titles)
- The reviewer then labels a small subset of the above dataset, which becomes your active learning system’s training data
- The selected active learning model learns from these labeled records based on the reviewer’s decisions, assigning a relevance score to all unlabeled documents and selecting new unlabeled records to present to the reviewer
- The reviewer then assesses the relevance of each suggested document, further refining the algorithm with each record
- Suggested documents are labeled and added to the training dataset. Repeat steps 3 through 5 until the required number of documents have been evaluated
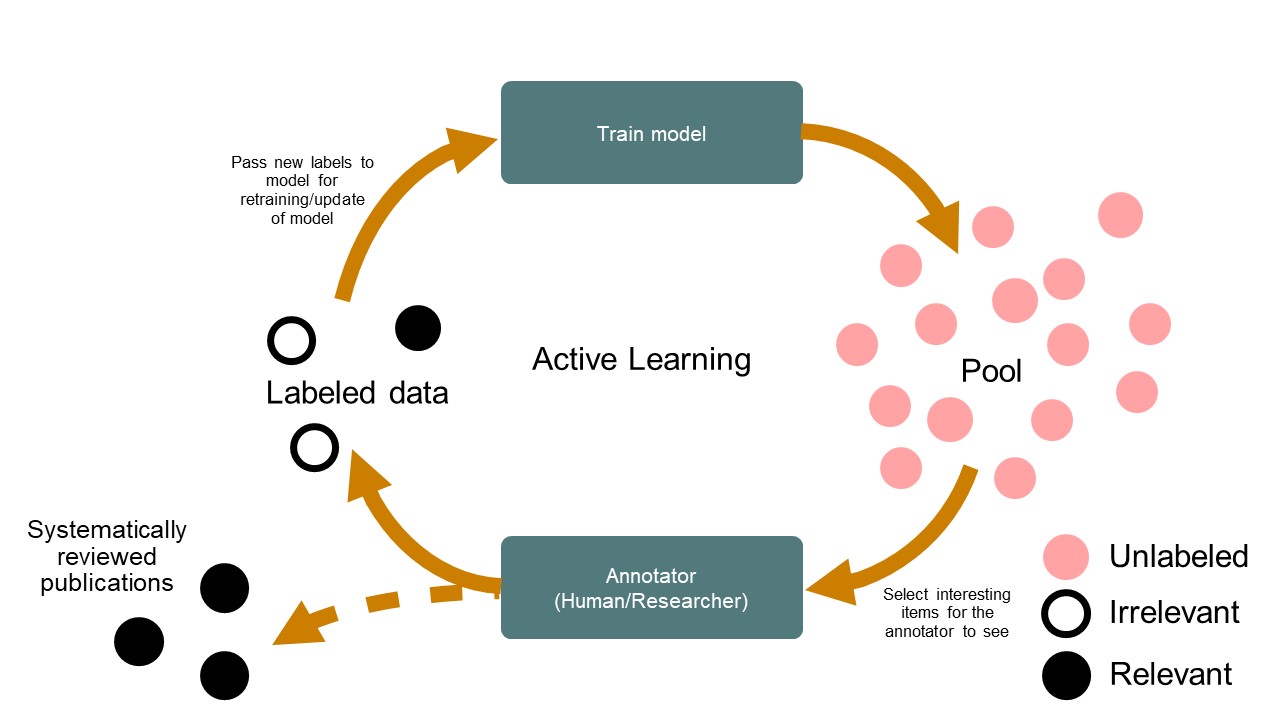
Image courtesy ASReview.
As the above workflow demonstrates, however, active learning models aren’t set-and-forget tools. Rather, the technology works hand-in-hand with researchers as a force multiplier, speeding up the task of article triage through well-informed suggestions and constant learning based on algorithm suggestions and researcher confirmation.
The above application to SLRs, also known as Researcher-in-the-Loop, must be performed systematically and should follow PRISMA guidelines.
Examples of active learning in systematic reviews
Several recent studies have demonstrated the time-saving value of active learning for SLRs. Here are a few of them:
- van Haastrecht et al. developed a systematic review methodology called SYMBALS (Systematic Review Methodology Blending Active Learning and Snowballing), which combines active learning and backward snowballing techniques. The researchers showed their methodology accelerates title and abstract screening by a factor of six.
- Singh et al. proposed a novelty-based active learning model “that works on exploring different topics during the initial phases of the active learning process and then proceeds based on relevance in the later phases,” adding that this model outperformed a naive active learning model in terms of the WSS@95 measurement.
- Wallace et al. developed a novel active learning model exploiting a priori domain knowledge supplied by a human expert, adding that this approach outperformed other active learning strategies on three real-world datasets.
CapeStart’s machine learning experts
The data scientists and machine learning engineers at CapeStart work with top-tier research organizations every day to improve SLR processes through active learning and other AI-based tools. Our experts in NLP and other machine learning techniques can help you quickly develop effective search protocols compliant with MEDDEV 2.7.1 (Rev. 4) from published sources such as Pubmed, Embase, and Cochrane.
Contact us today to set up a brief discovery call with our experts.